There is one thing that can get your wind up when you try to iterate quickly in a PR is to have a slow CI.
While working on a go project with a comprehensive test suite it was usually taking over 20 to 30 minutes to run and being as patient as a kid waiting for her candy floss to be ready I am eagerly waiting that my pipeline is Green or not.
My pipeline wasn’t that complicated, it’s a typical go project one, it has only a few steps which can be described like this :
- Checkout the git repo in a Tekton workspace (PVC) to the commit SHA we want to be tested.
- Run my functional/unit tests
- (I don’t have e2e tests yet :) but that should be step three when it’s done)
- Run some linting on my code with golangci-lint
- Run some other linters like yamllint.
As a good cloud native citizen Tekton spins up a new pod and attaches our pvc/workspace to it, and in each pods where a step is using go, the go compiler recompiles my dependencies I have vendored in my vendor directory.
I am vendoring inside my repository so at least I don’t have `go mod` downloading again and again, but the go compilation can get very slow.
At first, I made a large container with a large image that had all the tools (which is Tekton upstream test-runner image) to speeds by a good time albeit it was still relatively slow compared to running it on my laptop to run the testsuite.
I decided to go the “hacky way”, I would save the cache as often as possible to help the go compiler as much as possible.
This would use a toy project of mine called go-simple-uploader which is a simple go http server to upload and serve files to “cache my cache”.
At first I deployed the go-simple-uploader binary inside a kubernetes Deployment in front of a “Service”. The service will be accessible to every pod inside that same namespace, to its service name “http://uploader:8080”.
I modified my pipeline so at first step I would check if there is a cache file and uncompress it :
- image: mirror.gcr.io/library/golang:latest
name: get-cache
workingDir: $(workspaces.source.path)
script: |
#!/usr/bin/env bash
set -ex
mkdir -p go-build-cache;cd go-build-cache
curl -fsI http://uploader:8080/golang-cache.tar || {
echo "no cache found"
exit 0
}
echo "Getting cache"
curl http://uploader:8080/golang-cache.tar|tar -x -f-
This step does a few things :
- It uses the golang official image because I know it will be used later on in my pipeline so I don’t care as much to have a small image and I can use a bash/curl in there.
- It uses the source workspaces where I have my code checked out in from the git-clone task and create the go-build-cache directory
- If it finds the file called golang-cache.tar It uncompressed it as quickly as possible.
Later on in my pipeline, I have another task with multiple steps. I have moved away from using multiple tasks because PVC attachment can get quite slow. While a tekton task is a single pod where each steps are a container the steps looks like this :
- name: unitlint
runAfter:
- get-cache
taskSpec:
steps:
- name: unittest
image: mirror.gcr.io/library/golang:latest
workingDir: $(workspaces.source.path)
script: |
mkdir -p $HOME/.cache/ && ln -vs $(workspaces.source.path)/go-build-cache $HOME/.cache/go-build
make test
- name: lint
image: quay.io/app-sre/golangci-lint
workingDir: $(workspaces.source.path)
script: |
mkdir -p $HOME/.cache/ && ln -vfs $(workspaces.source.path)/go-build-cache $HOME/.cache/go-build
mkdir -p $HOME/.cache/ && ln -vfs $(workspaces.source.path)/go-build-cache $HOME/.cache/golangci-lint
make lint-go
This task run after `get-cache` the key part is where I symlink the go-build-cache directory to $HOME/.cache/go-build directory
Sames goes for golangci-lint I symlink its cache directory to $HOME/cache/golangci-lint
Later on I have another task that save this cache :
- name: save-cache
workingDir: $(workspaces.source.path)
script: |
#!/usr/bin/env bash
curl -o/dev/null -s -f -X POST -F path=test -F file=@/etc/motd http://uploader:8080/upload || {
echo "No cache server found"
exit 0
}
lm="$(curl -fsI http://uploader:8080/golang-cache.tar|sed -n '/Last-Modified/ { s/Last-Modified: //;s/\r//; p}')"
if [[ -n ${lm} ]];then
expired=$(python -c "import datetime, sys;print(datetime.datetime.now() > datetime.datetime.strptime(sys.argv[1], '%a, %d %b %Y %X %Z') + datetime.timedelta(days=1))" "${lm}")
[[ ${expired} == "False" ]] && {
echo "Cache is younger than a day"
exit
}
fi
cd $(workspaces.source.path)/go-build-cache
tar cf - . |curl -# -L -f -F path=golang-cache.tar -X POST -F "file=@-" http://uploader:8080/upload
The task starts by checking if you have a cache server and then with the help of some shell and python magic checking with the “Last-Modified” http header if you have a cache file that has already been generated since over a day.
I am doing this because at first I was using a uploading server in another environment which could get quite slow to upload on every run, since we run in the same namespace the upload is very fast so this is probably not needed, but keeping it here if someone else needs it.
It then uploads the cache file where it would be available for the subsequent runs using the first get-cache task.
Things got much faster, starting with my pipeline going over 10/12 minute at first run, it will get down to 2mn on the next runs. It gets as slow as your infra, the time for kubernetes to spin up the pods really, it could get under 1mn if I am running my pipeline under Kind.
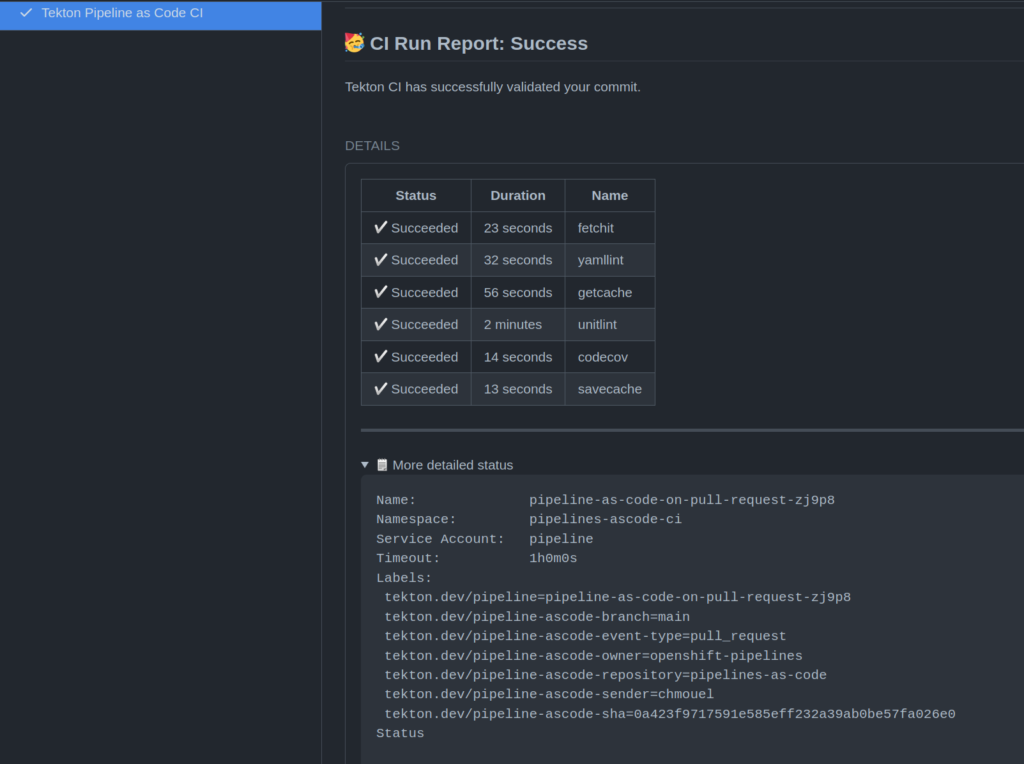
This is pretty KISS and may actually work on any pipelines that needs caching (I am looking at you java maven and nodejs npm).
Now the best way probably to address this in a generic way is to have a task in the tektoncd/catalog that behaves like the Github Action cache where the user can specify a parameter for the cache key, a TTL and a directory and maybe the storage type (ie: like an object storage or a simple http uploader or even another PVC) and the task automatically do everything at the start of your pipeline and by the end with in a finally task.
Hopefully we can get this done in the near future.